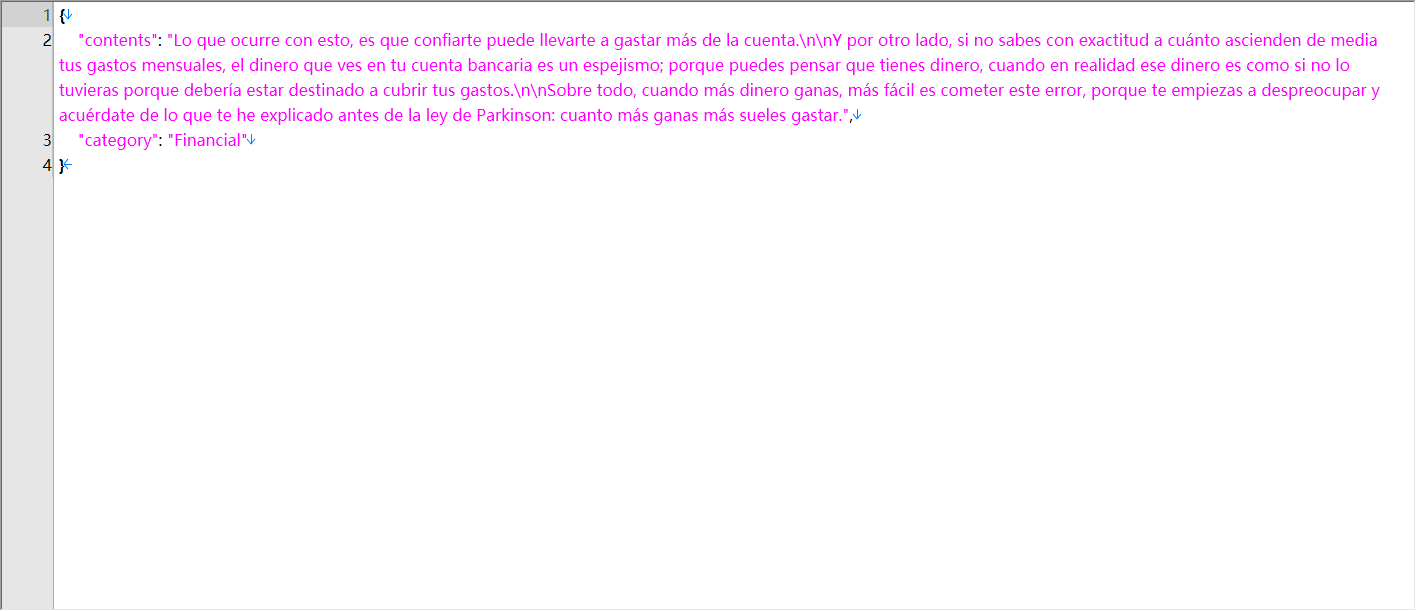
[{"@type":"PropertyValue","name":"Contenu des données","value":"200 000 textes en français, allemand, espagnol et italien"},{"@type":"PropertyValue","name":"Catégorie des données","value":"Plus de 200 catégories, notamment l’architecture, les animaux, l’automobile, la gastronomie, le cinéma, l’astrologie, la cybersécurité, etc."},{"@type":"PropertyValue","name":"Volume des données","value":"50 000 textes pour chaque langue : français, allemand, espagnol et italien"},{"@type":"PropertyValue","name":"Langue","value":"390 locuteurs natifs indiens, répartition équilibrée entre hommes et femmes"},{"@type":"PropertyValue","name":"Champ","value":"contents,category"},{"@type":"PropertyValue","name":"Format","value":"json"}]
{"id":1514,"datatype":"1","titleimg":"https://fr.nexdata.ai/shujutang/static/image/index/datatang_tuxiang_default.webp","type1":"226","type1str":null,"type2":"227","type2str":null,"dataname":"200 000 paires de textes en allemand, espagnol, français et italien","datazy":[{"title":"Contenu des données","desc":"Contenu des données","content":"200 000 textes en français, allemand, espagnol et italien"},{"title":"Catégorie des données","desc":"Catégorie des données","content":"Plus de 200 catégories, notamment l’architecture, les animaux, l’automobile, la gastronomie, le cinéma, l’astrologie, la cybersécurité, etc."},{"title":"Volume des données","desc":"Volume des données","content":"50 000 textes pour chaque langue : français, allemand, espagnol et italien"},{"title":"Langue","desc":"Langue","content":"390 locuteurs natifs indiens, répartition équilibrée entre hommes et femmes"},{"title":"Champ","desc":"Champ","content":"contents,category"},{"title":"Format","desc":"Format","content":"json"}],"datatag":"Network Data,German, French, Spanish, Italian","technologydoc":null,"downurl":null,"datainfo":null,"standard":null,"dataylurl":null,"flag":null,"publishtime":null,"createby":null,"createtime":null,"ext1":null,"samplestoreloc":null,"hosturl":null,"datasize":null,"industryPlan":null,"keyInformation":"","samplePresentation":[{"name":"德语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E5%BE%B7%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=Lt0IZkNRx6mg4wOEnhcb5NdEcmU%3D","intro":"","size":27326,"progress":100,"type":"jpg"},{"name":"法语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E6%B3%95%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=Q%2FBFyBvTvdUbH0K4B2lnwjIUgE8%3D","intro":"","size":26410,"progress":100,"type":"jpg"},{"name":"西班牙语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E8%A5%BF%E7%8F%AD%E7%89%99%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=xFYU8Jtl%2F%2B5PGtdm1TZQ0Tot%2F7A%3D","intro":"","size":23874,"progress":100,"type":"jpg"}],"officialSummary":"Ce corpus comprend 200 000 textes multilingues répartis équitablement entre le français, l’allemand, l’espagnol et l’italien (50 000 entrées par langue). Il couvre plus de 200 thématiques variées, dont l’architecture, les animaux, l’automobile, la restauration, le cinéma, l’astrologie et la cybersécurité. Cette ressource constitue une base solide pour l’apprentissage linguistique multilingue et l’analyse sémantique à grande échelle.","dataexampl":null,"datakeyword":["Données réseau"," allemand"," français"," espagnol"," italien"],"isDelete":null,"ids":null,"idsList":null,"datasetCode":null,"productStatus":null,"tagTypeEn":"Type","tagTypeZh":null,"website":null,"samplePresentationList":null,"datazyList":null,"keyInformationList":null,"dataexamplList":null,"bgimg":null,"datazyScriptList":null,"datakeywordListString":null,"sourceShowPage":"llm","dataShowType":"[{\"code\":\"0\",\"language\":\"ZH\"},{\"code\":\"1\",\"language\":\"ZH\"},{\"code\":\"2\",\"language\":\"EN,PT,DE,KO,FR,ES\"},{\"code\":\"3\",\"language\":\"EN\"},{\"code\":\"4\",\"language\":\"JP\"}]","productNameEn":"200000 text data in German, Spanish, French, and Italian","BGimg":"","voiceBg":["/shujutang/static/image/comm/audio_bg.webp","/shujutang/static/image/comm/audio_bg2.webp","/shujutang/static/image/comm/audio_bg3.webp","/shujutang/static/image/comm/audio_bg4.webp","/shujutang/static/image/comm/audio_bg5.webp"],"firstList":[{"name":"意大利语.png","url":"https://storage-product.datatang.com/damp/product/samplePresentation_ipad/20250718165755/%E6%84%8F%E5%A4%A7%E5%88%A9%E8%AF%AD.png?Expires=4102415999&OSSAccessKeyId=LTAI5tEBeSWUJiqjXvBMsxEu&Signature=wetCJjJuZysFpR%2FYpd2FRzdClEE%3D","intro":"","size":23350,"progress":100,"type":"jpg"}]}
200 000 paires de textes en allemand, espagnol, français et italien
Données réseau
allemand
français
espagnol
italien
Ce corpus comprend 200 000 textes multilingues répartis équitablement entre le français, l’allemand, l’espagnol et l’italien (50 000 entrées par langue). Il couvre plus de 200 thématiques variées, dont l’architecture, les animaux, l’automobile, la restauration, le cinéma, l’astrologie et la cybersécurité. Cette ressource constitue une base solide pour l’apprentissage linguistique multilingue et l’analyse sémantique à grande échelle.
Il s'agit d'un ensemble de données payant destiné à un usage commercial, à la recherche et plus encore. Ces Jeux de données prêts à l'emploi et sous licence contribuent au lancement de projets d'IA.
Spécifications
Contenu des données
200 000 textes en français, allemand, espagnol et italien
Catégorie des données
Plus de 200 catégories, notamment l’architecture, les animaux, l’automobile, la gastronomie, le cinéma, l’astrologie, la cybersécurité, etc.
Volume des données
50 000 textes pour chaque langue : français, allemand, espagnol et italien
Langue
390 locuteurs natifs indiens, répartition équilibrée entre hommes et femmes





 Spécifications
Spécifications Exemple
Exemple

 Jeux de données recommandés
Jeux de données recommandés




